В этой статье мы на примере рассмотрим один из статистических методов прогнозирования продаж. Мы будем прогнозировать прибыль, а точнее размер месячной прибыли. Совершенно аналогично можно делать прогнозы и других показателей продаж: выручка, объем продаж в натуральных единицах, количество сделок, количество новых клиентов и т.д.
Описанный в статье метод прост (относительно, конечно) и не привязан к специализированным программам. В принципе, для составления прогноза достаточно было бы бумаги, карандаша, калькулятора и линейки. Однако, это очень трудоемкий способ, поскольку в процессе возникает много рутинных вычислений. Поэтому мы будем использовать Microsoft Excel (версии 2000).
Помимо простоты у метода есть еще один важный плюс: для прогноза требуется небольшая статистика. Сделать прогноз на 2-3 месяца вперед можно, если есть статистика хотя бы за 13-14 месяцев. Ну а большая статистика дает возможность и прогноз делать на больший период.
Сбор и подготовка статистики продаж
Прогнозирование начинается, конечно, со сбора статистики продаж. Здесь нужно обращать внимание на то, чтобы все сделки были более-менее одного «масштаба», и чтобы количество сделок в месяц было достаточно большое.
Например, розничный магазин. Даже в небольшом магазине в месяц могут делаться тысячи и даже десятки тысяч покупок. Сумма каждой покупки, по сравнению с месячной выручкой, весьма мала — 0,0..01% от выручки. Это хорошая ситуация для прогнозирования.
Если прогноз делается для компании, работающей на корпоративном рынке, то нужно следить, чтобы количество сделок в месяц было хотя бы не менее 100, иначе для прогнозирования нужно применять другие методы. Также, если в статистике продаж встречаются крупные сделки, с суммой, например, около 10% от месячной выручки, то такие сделки надо исключать из статистики и рассматривать отдельно (опять же другими методами). Если крупные сделки не исключить, то они создадут в динамике «выбросы», которые могут сильно ухудшить точность прогноза.
По этим данным мы будем составлять прогноз на 12 месяцев вперед.
| Период | № Периода | Прибыль | Период | № Периода | Прибыль |
| 2004-7 | 1 | 839 | 2005-5 | 11 | 3069 |
| 2004-8 | 2 | 1714 | 2005-6 | 12 | 2220 |
| 2004-9 | 3 | 2318 | 2005-7 | 13 | 1653 |
| 2004-10 | 4 | 2629 | 2005-8 | 14 | 3115 |
| 2004-11 | 5 | 2823 | 2005-9 | 15 | 3961 |
| 2004-12 | 6 | 3320 | 2005-10 | 16 | 4514 |
| 2005-1 | 7 | 3316 | 2005-11 | 17 | 4644 |
| 2005-2 | 8 | 3479 | 2005-12 | 18 | 5066 |
| 2005-3 | 9 | 3388 | 2006-1 | 19 | 4934 |
| 2005-4 | 10 | 3263 | - | - | - |
Рис. 1. График помесячной прибыли, данные из таблицы .
Существуют две основные модели временного ряда: аддитивная и мультипликативная. Формула аддитивной модели: Y t = T t + S t + e t Формула мультипликативной модели: Y t = T t x St + e t Обозначения: t - время (месяц или другой период детализации); Y - значение величины; Т — тренд; S — сезонные изменения; е - шум. Разница между моделями хорошо видна на рисунке , где приведены два ряда, с одинаковыми трендами, один ряд — по мультипликативной модели, другой — по аддитивной.
-
Примечание. Могут встречаться такие показатели продаж, у которых сезонные колебания практически отсутствуют.

Рис. 2. Примеры рядов: слева — по аддитивной модели; справа — по мультипликативной.
В нашем примере мы будем использовать мультипликативную модель.
Для каких-либо других данных, возможно лучше подошла бы аддитивная модель. Узнать на практике, какая модель подходит лучше, можно либо интуитивно, либо методом проб и ошибок.
Выделение тренда
В формулах моделей рядов динамики (Y t = T t + S t + e t и Y t = T t S t + e t ) фигурирует тренд T t , такой тренд мы будем называть «точным».
В практических задачах выделить точный (вернее, «почти точный») тренд T t может оказаться технически очень сложно (см. например, пункт в списке литературы).
Поэтому мы будем рассматривать приближенные тренды. Самый простой способ получения приближенного тренда — сглаживание ряда методом скользящего среднего с периодом сглаживания равным максимальному периоду сезонных колебаний. Сглаживание почти полностью устранит сезонные колебания и шум.
В рядах с детализацией по месяцам сглаживание нужно делать по 12-ти точкам (то есть по 12-ти месяцам). Формула скользящего среднего с периодом сглаживания 12 месяцев:
![]()
Где M t — значение скользящего среднего в точке t ; Y t — значение величины временного ряда в точке t .
-
Примечание. Очень редко, но все-же бывают динамики продаж, где длина полного период не только не равна году, но и «плавает». В таких случаях колебания, видимо, вызваны не сезонными изменениями, а какими-то другими, более мощными факторами.
Обратите внимание: поскольку мы вычисляем некоторый средний тренд за последние 12 месяцев, то в поведении приближенного тренда по сравнению с точным, происходит как бы запаздывание на 6 месяцев. Не смотря на то, что тренд, полученный методом скользящего среднего — это не точный, а приближенный (да еще и с запаздыванием), он вполне подходит для нашей задачи.
Прологарифмируем уравнение мультипликативной модели, и если шум e t не очень большой, то получим аддитивную модель.
Здесь ε 1;t также обозначает шум. Тренд мы выделим (скользящим средним за 12 месяцев) именно для такой преобразованной модели. На рисунке 3 — графики и показателя и тренда M t .

Рис. 3. График прологарифмированной величины показателя и тренда М и
скользящего среднего по 12-ти месяцам. Слева на одном графике и величина и тренд. Справа — тренд в увеличенном масштабе. По оси X — номера периодов.
-
Примечание. Если темпы динамики небольшие, скажем, 10-15% в год, то и с мультипликативной моделью можно работать как с аддитивной (не логарифмирую).
Прогноз тренда
Тренд мы получили, теперь нужно его спрогнозировать. Прогноз можно бы было получить, например, методом экспоненциального сглаживания (см. ), но поскольку мы хотим прогнозировать максимально простым методом, то остановимся на обычной параметрической аппроксимации. В качестве функций приближения используем следующий набор:
Линейная функция: y = a + b × t.
Логарифмическая функция: y = a + b × ln(t)
Полином второй степени: y = a + b × t + c × t 2
Степенная функция: y = a × t b
Экспоненциальная функция: y = a × e b × t
Хорошо бы было дополнить набор и другими функциями, но для этого возможностей Excel недостаточно, нужно использовать специализированные программы: Maple, Matlab, MathCad и т.д.
Качество приближения мы будем оценивать по величине достоверности аппроксимации R 2 . Чем ближе эта величина к 1 — тем лучше функция приближает тренд. Это верно не всегда, но в Excel нет других критериев оценки качества аппроксимации. Впрочем, критерия R 2 нам будет достаточно.
На рисунках 4, 5, 6, 7 и 8и мы сделали аппроксимацию нашего тренда различными функциями и каждая функция аппроксимации продолжена на 12 точек вперед. И еще одна аппроксимация — на рисунке 9, полиномом 5-той степени.

Обратите внимание: если некоторая функция хорошо приближает тренд, то это не всегда означает, что данная функция хорошо тренд прогнозирует. В нашем примере полином 5-той степени делает самое лучшее приближение по сравнению с другими функциями (R 2 = 1) и, одновременно, дает самый нереальный прогноз.

По рисункам мы видим, что значение R 2 ближе всего к единице у параболы (полином 5-той степени уже не рассматриваем). Следующая по качеству аппроксимация — прямая линия. Хотя формально парабола аппроксимирует лучше всех, но ее поведение, особенно перевал в отдаленных точках, представляется не очень правдоподобным. Тогда можно взять аппроксимацию прямой, но мы найдем компромисс: среднее арифметическое между параболой и прямой.

Рис. 10. Тренд M t и его прогноз. По оси X — номер периода.
Результат прогноза тренда M t — на рисунке 10. Итак, мы получили прогноз тренда.
Прогноз показателя
Прогноз тренда у нас есть. Теперь можно сделать прогноз самого показателя. Формула очевидна:
Ln(Y t+1) = 12 × M t+1 - Ln(Y t) - Ln(Y t-1) - ... - Ln(Y t-10)
Y t+1 = exp(Ln(Y t+1))
До периода t = 19 у нас есть фактические данные. Для t = 20..31 у нас есть спрогнозированный тренд M t , а значения показателя мы будем считать последовательно, сначала для t = 20, потом для t = 21 и т.д.
Результаты прогноза — на рисунке 11 и в таблице 2.
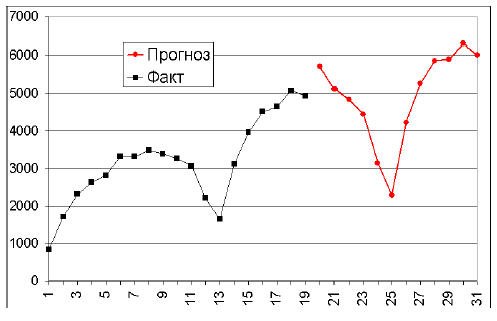
Рис. 11. Прогноз показателя. По оси X — номер периода.
Сравнение прогноза и реальных данных
На рисунке 12 — графики прогноза и фактических данных.
В таблице 3 приведено сравнение реальных данных и спрогнозированных. Посчитаны ошибки прогноза, абсолютные: Прогноз-Факт; и относительные: 100%*(Прогноз-Факт)/Факт.
Обратите внимание, что ошибки прогноза смещены в положительную сторону. Причина этого может быть как в несовершенстве метода, так и в каких-то объективных обстоятельствах, например, в изменении ситуации на рынке в прогнозируемом периоде.
Точность прогноза
| Период | № Периода | М | Ln(Y) | Y |
| 2006-2 | 20 | 8,1861 | 8,6494 | 5707 |
| 2006-3 | 21 | 8,2205 | 8,5408 | 5119 |
| 2006-4 | 22 | 8,2531 | 8,4816 | 4825 |
| 2006-5 | 23 | 8,2839 | 8,3987 | 4441 |
| 2006-6 | 24 | 8,3129 | 8,0533 | 3144 |
| 2006-7 | 25 | 8,3401 | 7,7367 | 2291 |
| 2006-8 | 26 | 8,3655 | 8,3488 | 4225 |
| 2006-9 | 27 | 8,3891 | 8,5675 | 5258 |
| 2006-10 | 28 | 8,4109 | 8,6765 | 5864 |
| 2006-11 | 29 | 8,4309 | 8,6833 | 5904 |
| 2006-12 | 30 | 8,4491 | 8,7487 | 6303 |
| 2007-1 | 31 | 8,4655 | 8,7007 | 6007 |

Рис. 12. Фактические данные и спрогнозированные. По оси X — номер периода.
Даже если модель очень хорошо описывает динамику реальных данных, что в общем-то большая редкость, то остаются еще шумы, которые вносят свою ошибку. Например, если уровень шума составляет 10% от значения показателя, то и ошибка прогноза будет не меньше 10%. Плюс, как минимум, еще несколько процентов ошибки добавятся из-за несоответствия модели и динамики реальных данных.
А вообще, лучший способ определить точность — это многократно делать прогнозы для одного и того же процесса и на основании такого опыта определять точность эмпирически.
| Период | № Периода | Факт | Прогноз | Ошибка, абс. | Ошибка, % |
| 2006-2 | 20 | 5233 | 5707 | 474 | 9 |
| 2006-3 | 21 | 4625 | 5119 | 494 | 11 |
| 2006-4 | 22 | 4776 | 4825 | 49 | 1 |
| 2006-5 | 23 | 4457 | 4441 | -16 | 0 |
| 2006-6 | 24 | 3169 | 3144 | -25 | -1 |
| 2006-7 | 25 | 2054 | 2291 | 237 | 12 |
| 2006-8 | 26 | 3549 | 4225 | 676 | 19 |
| 2006-9 | 27 | 5087 | 5258 | 171 | 3 |
| 2006-10 | 28 | 5187 | 5864 | 677 | 13 |
| 2006-11 | 29 | 5287 | 5904 | 617 | 12 |
| 2006-12 | 30 | 5700 | 6303 | 603 | 11 |
| 2007-1 | 31 | 4689 | 6007 | 1318 | 28 |
Заключение и список литературы
В этой статье мы рассмотрели сильно упрощенный метод прогнозирования. Тем не менее, при отсутствии резких изменений на рынке и внутри компании, даже такой простой метод дает удовлетворительную точность прогноза месяцев на 10 вперед.
Литература
1. Крамер Г. «Математические методы статистики».— М.: «Мир», 1975.
2. Кендэл М. «Временные ряды».— М.: «Финансы и статистика», 1981.
3. Андерсон Т. «Статистический анализ временных рядов».— М.: «Мир», 1976.
4. Бокс Дж., Дженкис Г. «Анализ временных рядов. Прогноз и управление».— М.: «Мир», 1976
5. Губанов В.А., Ковальджи А.К. «Выделение сезонных колебаний на основе вариационных принципов. Экономика и математические методы». 2001. т. 37. № 1. С. 91-102.
Компании – качественное прогнозирование продаж. Правильно рассчитанный прогноз позволяет более эффективно вести бизнес, прежде всего, контролировать и оптимизировать расходы. Кроме того, если речь идет о продукции, это позволяет сформировать оптимальные (а не завышенные или заниженные) запасы продукции на складе.
Очень важно, чтобы менеджер по продажам имел представление о том, что произойдет в будущем, поскольку это поможет ему планировать свои действия в случае возникновения тех или иных событий. Многие менеджеры по продажам не признают того, что прогнозирование объема продаж является одной из их обязанностей и оставляют это на усмотрение бухгалтеров, которым необходимо заниматься прогнозированием для составления бюджетов.
Возможно, менеджеры по продажам просто не понимают, зачем им необходимо такое прогнозирование, так как полагают, что гораздо более важной их задачей являются сами продажи. И действительно, задача прогнозирования менеджером по продажам формулируется часто нечетко и поэтому выполняется так же: торопливо, без соответствующей научной базы. Результаты подобного прогнозирования нередко ненамного лучше, чем простая догадка.
Цели прогнозирования объема продаж
Цель прогнозирования объема продаж - позволить менеджерам заранее планировать деятельность наиболее эффективным образом. Следует еще раз подчеркнуть, что именно менеджер по продажам является тем человеком, который должен отвечать за эту задачу. У бухгалтера нет возможностей предсказывать, будет ли рынок подниматься или падать; все, что он может сделать в этих условиях, - это экстраполировать результаты на основе предыдущих продаж, оценивать общий тренд и делать прогнозы на основе этого. Именно менеджер по продажам является тем человеком, который должен знать, в каком направлении двигается рынок, и если задача прогнозирования объема продаж оставляется на усмотрение бухгалтера, это означает, что менеджер по продажам игнорирует важнейшую часть своих обязанностей. Кроме того, к процедуре прогнозирования объема продаж следует подходить серьезно, поскольку из нее вытекает планирование всего бизнеса; если прогноз является ошибочным, то и планы будут такими же неточными.
То есть планирование вытекает из прогнозирования объема продаж, и целью планирования является распределение ресурсов компании таким образом, чтобы обеспечить эти ожидаемые продажи. Компания может прогнозировать свой объем продаж либо на основе продаж на рынке в целом (что называется прогнозом рынка), определяя свою долю в этом объеме, либо прогнозировать непосредственно свой объем продаж.
Самым простым способом прогнозирования рыночной ситуации является экстраполяция, т.е. распространение тенденций, сложившихся в прошлом, на будущее. Сложившиеся объективные тенденции изменения экономических показателей в известной степени предопределяют их величину в будущем.
К тому же многие рыночные процессы обладают некоторой инерционностью. Особенно это проявляется в краткосрочном прогнозировании. В то же время прогноз на отдаленный период должен максимально принимать во внимание вероятность изменения условий, в которых будет функционировать рынок.
Методы прогнозирования объема продаж
Объема продаж можно разделить на три основные группы:
Методы экспертных оценок;
и прогнозирования временных рядов;
казуальные (причинно-следственные) методы.
Основываются на субъективной оценке текущего момента и перспектив развития. Эти методы целесообразно использовать для оценок, особенно в случаях, когда невозможно получить непосредственную информацию о каком-либо явлении или процессе.
Вторая и третья группы методов основаны на анализе количественных показателей, но они существенно отличаются друг от друга.
Методы анализа и прогнозирования динамических рядов связаны с исследованием изолированных друг от друга показателей, каждый из которых состоит из двух элементов: из прогноза детерминированной компоненты и прогноза случайной компоненты. Разработка первого прогноза не представляет больших трудностей, если определена основная тенденция развития и возможна ее дальнейшая экстраполяция. Прогноз случайной компоненты сложнее, так как ее появление можно оценить лишь с некоторой вероятностью.
В основе казуальных методов лежит попытка найти факторы, определяющие поведение прогнозируемого показателя. Поиск этих факторов приводит собственно к экономико-математическому моделированию - построению модели поведения экономического объекта, учитывающей развитие взаимосвязанных явлений и процессов. Следует отметить, что применение многофакторного прогнозирования требует решения сложной проблемы выбора факторов, которая не может быть решена чисто статистическим путем, а связана с необходимостью глубокого изучения экономического содержания рассматриваемого явления или процесса.
Каждая из рассмотренных групп методов обладает определенными достоинствами и недостатками. Их применение более эффективно в краткосрочном прогнозировании, так как они в определенной мере упрощают реальные процессы и не выходят за рамки представлений сегодняшнего дня. Следует обеспечивать одновременное использование количественных и качественных методов прогнозирования.
Необходимо разделять прогнозы на долгосрочные (на 1, 3, 5 или больше лет) и кратко- или среднесрочные (неделя, месяц, квартал). Прогнозы на более длинные периоды обычно менее точные (хотя и не всегда). Это понятно, ведь больше факторов могут на протяжении длительного периода времени скорректировать ожидаемые результаты в ту или другую сторону. Однако вполне реально сделать точные прогнозы деятельности вашего предприятия для любого промежутка времени.
Точный прогноз – это прогноз, который имеет отклонение от реальных объемов продаж в пределах 10% в большую или меньшую сторону. Например, вы спрогнозировали, что за период 3 месяцев продадите продукции в размере 1000 шт. В конце периода вы получили результат 900, или же 1100 шт. или любую цифру в этом промежутке. Такой прогноз можно считать точным и качественным. Если отклонения существенны (вместо прогнозируемой цифры 1000 шт. получен результат – 500 шт.) – это свидетельствует о некорректном, слишком завышенном прогнозе, или же о форс-мажорных обстоятельствах, которые повлекли за собой резкое падение объемов продаж.
Как построить точный прогноз
Эта работа состоит из нескольких этапов:
Запишите точные результаты деятельности за предыдущие промежутки времени (например, ежемесячные продажи вашей продукции на протяжении последнего года). Если ваша продукция новая и не имеет истории продаж, вам придется подождать 2-3 месяца, чтобы получить информацию о первых продажах. Без этого попытки построить точный прогноз, основываясь лишь на предположениях, будут напрасны.
Рассчитайте коэффициенты сезонности. Сформируйте график, который показал бы объем продаж на протяжении определенного отрезка времени. Для этого возьмите за основу, например, один из месяцев и сравните с объемами продаж в следующие месяцы. Важно знать, есть товары и услуги, спрос на которые имеет незначительные, иногда малозаметные сезонные колебания. Однако в таких сферах, как туристические услуги или же продажа пищевых продуктов, сезонные колебания очень значительные. Понятно, что если ваша фирма занимается продажами туристических путевок в дома отдыха Крыма, и в марте вы продали, например, 100 путевок, на июнь планируйте продажи в несколько раз выше. А на июль-август прогноз должен быть еще выше. В сфере питания вопрос точного прогнозирования продаж стоит острее, ведь продукция имеет сроки хранения, на протяжении которых ее нужно сбыть. Потому рассчитайте коэффициенты сезонности для каждого планового отрезка и запишите их.
Пример: вы занимаетесь продажами безалкогольных напитков. В начале мая вы должны рассчитать прогноз продаж на июль. У вас есть данные по продажам за каждый месяц предыдущего года, в частности, в апреле (5 000 шт.) и июле (12 000 шт.) прошлого года, а также за апрель этого года (7 000 шт.). Для того, чтобы определить коэффициент сезонности, нужно получить соотношение продаж за июль прошлого года к количеству продаж в апреле того же года. Полученную цифру (коэффициент сезонности) нужно перемножить на данные по количеству продаж за апрель этого года. В результате получим прогноз продаж на июль, взвешенный на коэффициент сезонности: 12 000/5 000 = 2,4. 7 000*2,4 = 16 800 шт. – прогноз на июль. Если другие факторы, которые влияют на объем продаж, остались неизменными, этот прогноз будет очень точным.
Рассчитайте по цене на вашу продукцию. Тут не помешает вспомнить студенческий курс экономики. Определите, как изменялся спрос после изменения цен на вашу продукцию. Если спрос на вашу продукцию имеет высокую (то есть, заметно падал при росте цен), пытайтесь в дальнейшем избегать значительного повышения стоимости продукции для ваших потребителей, и ни в коем случае не поднимайте цены раньше, чем ваши конкуренты.
Пример: данные свидетельствуют: при повышении цены на 1% спрос на вашу продукцию падает на 2,5%. Вы планируете в июне повысить цену на 10%, это повлечет падение спроса на 25%. В прошлом году в этот же период цена оставалась неизменной. Продажи апреля составили 400 шт., коэффициент сезонности – 3,0. Рассчитываем прогноз на июль: 400*3*(100%-25%)=900 шт.
Учтите рост производственных мощностей (или открытие новых магазинов, точек сбыта продукции). Если вы расширяете производство, выходите на новые рынки сбыта, обязательно учтите это в прогнозе.
Пример: раньше вы поставляли продукцию лишь в своем городе. Начиная со следующего месяца, вы начинаете сотрудничество с посредниками из других городов и открываете дополнительно 5 точек продаж. На данный момент 10 точек продаж сбывают 2 000 шт. продукции на месяц. Таким образом, ожидаемые продажи 15 точек дадут результат около 3 000 шт.
Рассчитайте коэффициент влияния внешних факторов (в первую очередь общеэкономической ситуации в государстве и конкурентов). Для расчета этого коэффициента вы должны тщательным образом отслеживать ваш рынок и следить за появлением новых игроков. Очень часто компании не учитывают инновации конкурентов, их деятельность на рынке. И в результате получают более низкие показатели, чем ожидали изначально. Как рассчитать коэффициент внешних факторов? Для этого нужно иметь историю продаж за длительный период (хотя бы 2 года, желательно больше). Рассчитайте прогноз продаж на прошлый год по данным позапрошлого (с учетом коэффициентов сезонности и эластичности). Сравните прогноз с реальными цифрами. Из разницы, которая вышла, высчитайте форс-мажорные обстоятельства. Остальные – это и есть показатель влияния внешних факторов.
Пример: вы имеете коэффициенты сезонности и эластичности спроса на вашу продукцию. Допустимо, суммарные продажи позапрошлого года составили 10 000 шт., суммарные продажи в прошлом году составили 14 000 шт. с учетом коэффициента эластичности прогноз на прошлый год должен был составить 9 000 шт. Однако увеличение объемов сбыта позволило увеличить объемы продаж вдвое (вдвое расширили штат работников отдела продаж и открыли еще 2 точки продаж дополнительно до двух существующих, как и было до этого). Это увеличивает прогноз до 18 000 шт. Следовательно, фактическое отклонение составило 4 000 шт. из них 2 000 шт. не было продано по причине непредвиденные обстоятельств – форс-мажор (проблемы с поставщиками сырья на протяжении двух месяцев). Отклонение, связанное с влиянием внешних факторов, составило 2 000 шт. (18 000 – 14 000 – 2 000). Коэффициент влияния составит таким образом: 1-(2 000 влияние внешних факторов /18 000 прогноз -2 000 форс-мажор)=0,875
Ознакомьте с прогнозом продаж каждого работника из отдела продаж (сбыта). Отметьте, что эти цифры получены на основе точных расчетов с учетом всех факторов. Это еще одна важная деталь, ведь работники будут знать, какие цифры от них ожидаются и что эти цифры не вымышленные, а вполне обоснованы реальными расчетами.
Создание точных прогнозов продаж позволит вам более эффективно использовать имеющиеся ресурсы, сократить расходы, правильно разработать планы работы, оптимизировать деятельность вашей компании, в том числе сектора продаж.
Прогнозирование – это очень важный элемент практически любой сферы деятельности, начиная от экономики и заканчивая инженерией. Существует большое количество программного обеспечения, специализирующегося именно на этом направлении. К сожалению, далеко не все пользователи знают, что обычный табличный процессор Excel имеет в своем арсенале инструменты для выполнения прогнозирования, которые по своей эффективности мало чем уступают профессиональным программам. Давайте выясним, что это за инструменты, и как сделать прогноз на практике.
Целью любого прогнозирования является выявление текущей тенденции, и определение предполагаемого результата в отношении изучаемого объекта на определенный момент времени в будущем.
Способ 1: линия тренда
Одним из самых популярных видов графического прогнозирования в Экселе является экстраполяция выполненная построением линии тренда.
Попробуем предсказать сумму прибыли предприятия через 3 года на основе данных по этому показателю за предыдущие 12 лет.

Способ 2: оператор ПРЕДСКАЗ
Экстраполяцию для табличных данных можно произвести через стандартную функцию Эксель ПРЕДСКАЗ . Этот аргумент относится к категории статистических инструментов и имеет следующий синтаксис:
ПРЕДСКАЗ(X;известные_значения_y;известные значения_x)
«X» – это аргумент, значение функции для которого нужно определить. В нашем случае в качестве аргумента будет выступать год, на который следует произвести прогнозирование.
«Известные значения y» — база известных значений функции. В нашем случае в её роли выступает величина прибыли за предыдущие периоды.
«Известные значения x» — это аргументы, которым соответствуют известные значения функции. В их роли у нас выступает нумерация годов, за которые была собрана информация о прибыли предыдущих лет.
Естественно, что в качестве аргумента не обязательно должен выступать временной отрезок. Например, им может являться температура, а значением функции может выступать уровень расширения воды при нагревании.
При вычислении данным способом используется метод линейной регрессии.
Давайте разберем нюансы применения оператора ПРЕДСКАЗ на конкретном примере. Возьмем всю ту же таблицу. Нам нужно будет узнать прогноз прибыли на 2018 год.


Но не стоит забывать, что, как и при построении линии тренда, отрезок времени до прогнозируемого периода не должен превышать 30% от всего срока, за который накапливалась база данных.
Способ 3: оператор ТЕНДЕНЦИЯ
Для прогнозирования можно использовать ещё одну функцию – ТЕНДЕНЦИЯ . Она также относится к категории статистических операторов. Её синтаксис во многом напоминает синтаксис инструмента ПРЕДСКАЗ и выглядит следующим образом:
ТЕНДЕНЦИЯ(Известные значения_y;известные значения_x; новые_значения_x;[конст])
Как видим, аргументы «Известные значения y» и «Известные значения x» полностью соответствуют аналогичным элементам оператора ПРЕДСКАЗ , а аргумент «Новые значения x» соответствует аргументу «X» предыдущего инструмента. Кроме того, у ТЕНДЕНЦИЯ имеется дополнительный аргумент «Константа» , но он не является обязательным и используется только при наличии постоянных факторов.
Данный оператор наиболее эффективно используется при наличии линейной зависимости функции.
Посмотрим, как этот инструмент будет работать все с тем же массивом данных. Чтобы сравнить полученные результаты, точкой прогнозирования определим 2019 год.


Способ 4: оператор РОСТ
Ещё одной функцией, с помощью которой можно производить прогнозирование в Экселе, является оператор РОСТ. Он тоже относится к статистической группе инструментов, но, в отличие от предыдущих, при расчете применяет не метод линейной зависимости, а экспоненциальной. Синтаксис этого инструмента выглядит таким образом:
РОСТ(Известные значения_y;известные значения_x; новые_значения_x;[конст])
Как видим, аргументы у данной функции в точности повторяют аргументы оператора ТЕНДЕНЦИЯ , так что второй раз на их описании останавливаться не будем, а сразу перейдем к применению этого инструмента на практике.


Способ 5: оператор ЛИНЕЙН
Оператор ЛИНЕЙН при вычислении использует метод линейного приближения. Его не стоит путать с методом линейной зависимости, используемым инструментом ТЕНДЕНЦИЯ . Его синтаксис имеет такой вид:
ЛИНЕЙН(Известные значения_y;известные значения_x; новые_значения_x;[конст];[статистика])
Последние два аргумента являются необязательными. С первыми же двумя мы знакомы по предыдущим способам. Но вы, наверное, заметили, что в этой функции отсутствует аргумент, указывающий на новые значения. Дело в том, что данный инструмент определяет только изменение величины выручки за единицу периода, который в нашем случае равен одному году, а вот общий итог нам предстоит подсчитать отдельно, прибавив к последнему фактическому значению прибыли результат вычисления оператора ЛИНЕЙН , умноженный на количество лет.


Как видим, прогнозируемая величина прибыли, рассчитанная методом линейного приближения, в 2019 году составит 4614,9 тыс. рублей.
Способ 6: оператор ЛГРФПРИБЛ
Последний инструмент, который мы рассмотрим, будет ЛГРФПРИБЛ . Этот оператор производит расчеты на основе метода экспоненциального приближения. Его синтаксис имеет следующую структуру:
ЛГРФПРИБЛ (Известные значения_y;известные значения_x; новые_значения_x;[конст];[статистика])
Как видим, все аргументы полностью повторяют соответствующие элементы предыдущей функции. Алгоритм расчета прогноза немного изменится. Функция рассчитает экспоненциальный тренд, который покажет, во сколько раз поменяется сумма выручки за один период, то есть, за год. Нам нужно будет найти разницу в прибыли между последним фактическим периодом и первым плановым, умножить её на число плановых периодов (3) и прибавить к результату сумму последнего фактического периода.


Прогнозируемая сумма прибыли в 2019 году, которая была рассчитана методом экспоненциального приближения, составит 4639,2 тыс. рублей, что опять не сильно отличается от результатов, полученных при вычислении предыдущими способами.
Мы выяснили, какими способами можно произвести прогнозирование в программе Эксель. Графическим путем это можно сделать через применение линии тренда, а аналитическим – используя целый ряд встроенных статистических функций. В результате обработки идентичных данных этими операторами может получиться разный итог. Но это не удивительно, так как все они используют разные методы расчета. Если колебание небольшое, то все эти варианты, применимые к конкретному случаю, можно считать относительно достоверными.
Аппроксимация функции нескольких независимых переменных (множественная регрессия) – очень интересная, имеющая огромное практическое значение задача! Если научиться ее решать, то можно стать почти волшебником, умеющим делать очень достоверные прогнозы...
Результатов различных процессов на основе данных предыдущих периодов времени. В этой статье мы рассмотрим прогнозирование в Excel при помощи очень мощного и удобного инструмента — встроенных статистических функций ЛИНЕЙН и ЛГРФПРИБЛ.
Не пугайтесь «умных» терминов! Все, на самом деле, не так страшно, как кажется вначале! Не пожалейте время и прочтите эту статью внимательно до конца. Умение применять на практике эти функции существенно увеличит ваш «вес» как специалиста в глазах коллег, руководителей и в своих собственных глазах!
В одной из самых популярных статей этого блога подробно рассказано об (рекомендую прочесть). Но в реальных жизненных процессах результат, как правило, зависит от многих независимых друг от друга факторов (переменных). Как выявить и учесть все эти факторы, связать их воедино и на основании накопленных статистических данных спрогнозировать расчетный конечный результат для некоего нового набора исходных параметров? Как оценить достоверность прогноза и степень влияния на результат каждой из переменных? Ответы на эти и другие вопросы – далее в тексте статьи.
Что можно научиться прогнозировать? Очень многое! В принципе, можно научиться прогнозировать любые самые разнообразные результаты процессов в повседневной жизни и работе. Всегда, когда возникает вопрос: «А что будет, если…?» зовите на помощь Excel, рассчитывайте прогноз и проверяйте его достоверность!
Можно научиться прогнозировать зависимость прибыли от цены и объемов продаж любого товара.
Можно научиться прогнозировать зависимость цены автомобилей на вторичном рынке от марки, мощности, комплектации, года выпуска, количества предыдущих владельцев, пробега.
Можно научиться устанавливать зависимость объемов продаж товаров от затрат на различные виды рекламы.
Можно научиться выполнять прогнозирование в Excel стоимости наборов любых услуг в зависимости от их состава и качества.
В производстве, используя косвенные простые параметры, можно научиться прогнозировать трудоемкость и объем выпускаемой продукции, потребление материалов и энергоресурсов, и т.д.
Прежде чем начать решать практическую задачу, хочу обратить внимание на один весьма важный момент. Научиться выполнять прогнозирование в Excel с использованием вышеназванных функций ЛИНЕЙН и ЛГРФПРИБЛ технически не очень сложно. Гораздо сложнее научиться анализировать процесс, приводящий к результату и находить простые факторы, влияющие на него. При этом желательно (но не обязательно) понимать — КАК зависит результат (функция) от каждого из факторов (переменных). Линейная это зависимость или может быть степенная или какая-нибудь другая? Понимание физического смысла процесса поможет вам правильно выбрать переменные. Подбор аппроксимирующей функции следует производить при полном понимании логики и смысла процесса, приводящего к результату.
Подготовка к прогнозированию в Excel.
1. Четко формулируем название и единицу измерения интересующего нас результата процесса. Это и есть искомая функция — y , аналитическое выражение которой мы будем определять с помощью MS Excel.
В примере, представленном чуть ниже, y — это срок изготовления заказа в рабочих днях.
2. Производим анализ процесса и выявляем факторы — аргументы функции — x 1 , x 2 , ... x n — наиболее сильно на наш взгляд влияющие на результат – значения функции y . Внимательно назначаем единицы измерений для переменных.
В примере это:
x 1 — суммарная длина всех прокатных профилей в метрах, из которых изготавливается заказ
x 2 — общая масса всех прокатных профилей в килограммах
x 3 — суммарная площадь всех листов в метрах квадратных
x 4 — общая масса всех листов в килограммах
3. Собираем статистику – фактические данные – в виде таблицы.
В примере – это фактические данные о металлопрокате и фактических сроках выполненных ранее заказов.
Очень важно при выборе переменных x 1 , x 2 , ... x n учесть их доступность. То есть, значения этих факторов должны быть у вас в виде достоверных статистических данных. Очень желательно, чтобы получение значений статистических данных было простым, понятным и нетрудоемким процессом.
Переходим непосредственно к рассмотрению примера.
Небольшой участок завода производит строительные металлоконструкции. Входным сырьем является листовой и профильный металлопрокат. Мощность участка в рассматриваемом периоде времени неизменна. В наличии есть статистические данные о сроках изготовления 13-и заказов (k =13) и количестве использованного металлопроката. Попробуем найти зависимость срока изготовления заказа от суммарной длины и массы профильного проката и суммарной площади и массы листового проката.
В рассмотренном примере срок изготовления заказа напрямую зависит от мощности производства (люди, оборудование) и трудоемкости выполнения технологических операций. Но детальные технологические расчеты очень трудоемки и, соответственно, длительны и дороги. Поэтому в качестве аргументов функции выбраны четыре параметра, которые легко и быстро можно посчитать при наличии спецификации металлопроката, и которые косвенно влияют на результат – срок изготовления. В результате анализа была установлена сильнейшая связь между изменениями исходных данных и результатами процесса изготовления металлоконструкций.
Примечательно, что найденная зависимость связывает в одной формуле параметры с различными единицами измерения. Это нормально. Найденные коэффициенты не являются безразмерными. Например, размерность коэффициента b – рабочие дни, а коэффициента m 1 – рабочие дни/м.
1. Запускаем MS Excel и заполняем ячейки B4...F16 таблицы Excel исходными статистическими данными. В столбцы пишем значения переменных x i и фактические значения функции y , располагая данные, относящиеся к одному заказу в одной строке.

2. Так как функции ЛИНЕЙН и ЛГРФПРИБЛ — функции выводящие результаты в виде массива , то их ввод имеет некоторые особенности. Выделяем область размером 5×5 ячеек — ячейки I9...M13. Количество выделенных строк всегда — 5, а количество столбцов должно быть равно количеству переменных x i плюс 1. В нашем случае это: 4+1=5.
3. Нажимаем на клавиатуре клавишу F2 и набираем формулу
в ячейках I9...M13: =ЛИНЕЙН(F4:F16;B4:E16;ИСТИНА;ИСТИНА)
4. После набора формулы необходимо для ее ввода нажать сочетание клавиш Ctrl+Shift+Enter. (Знак «+» нажимать не нужно, в записи он означает, что клавиши нажимаются последовательно при удержании нажатыми всех предыдущих.)
5. Считываем результаты работы функции ЛИНЕЙН в ячейках I9...M13.
Карту, поясняющую значения каких параметров в каких ячейках выводятся, я расположил в ячейках I4...M8 для удобства чтения сверху над массивом значений.
Общий вид уравнения аппроксимирующей функции y , представлен в объединенных ячейках I2...M2.

Значения коэффициентов b , m 1 , m 2 , m 3 , m 4 считываем соответственно
в ячейке M9: b =4,38464164
в ячейке L9: m 1 =0,002493053
в ячейке K9: m 2 =0,000101103
в ячейке J9: m 3 =-0,084844006
в ячейке I9: m 4 =0,002428953
6. Для определения расчетных значений функции y — срока изготовления заказа — вводим формулу
в ячейку G4: =$L$9*B4+$K$9*C4+$J$9*D4+$I$9*E4+$M$9 =5,0
y =b +m 1 *x 1 +m 2 *x 2 +m 3 *x 3 +m 4 *x 4
7. Копируем эту формулу во все ячейки столбца от G5 до G17 «протягиванием» и сверяем расчетные значения с фактическими. Совпадение очень хорошее!
8. Предварительные действия все выполнены. Уравнение аппроксимирующей функции y найдено. Пробуем выполнить прогнозирование в Excel срока изготовления нового заказа. Вписываем исходные данные.
8.1. Длину прокатных профилей по проекту x 1 в метрах пишем
в ячейку B17: 2820
8.2. Массу прокатных профилей x 2 в килограммах пишем
в ячейку C17: 62000
8.3. Площадь листового проката, используемого в новом заказе по проекту, x 3 в метрах квадратных заносим
в ячейку D17: 110,0
8.4. Общую массу листового проката x 4 в килограммах вписываем
в ячейку E17: 7000
9. Расчетный срок изготовления заказа y в рабочих днях считываем
в ячейке G17: =$L$9*B17+$K$9*C17+$J$9*D17+$I$9*E17+$M$9 =25,4
Прогнозирование в Excel выполнено. На основе статистических данных мы рассчитали предположительный срок выполнения нового заказа — 25,4 рабочих дней. Остается выполнить заказ и сверить фактическое время с прогнозным.
Анализ результатов.
Мы не будем погружаться глубоко в дебри статистических терминов и расчетов, но некоторых практических аспектов все же придется коснуться.
Обратимся к другим данным в массиве, которые вывела функция ЛИНЕЙН.
Во второй строке массива в ячейках I10…M10 выведены стандартные ошибки se 4 , se 3 , se 2 , se 1 , se b для расположенных выше в первой строке массива соответствующих коэффициентов уравнения аппроксимирующей функции m 4 , m 3 , m 2 , m 1 , b .
В третьей строке в ячейке I11 выведено значение коэффициента множественной детерминации r 2 , а в ячейке J11 — стандартная ошибка для функции — se y .
В четвертой строке в ячейке I12 находится, так называемое F -наблюдаемое значение, а в ячейке J12 — df – количество степеней свободы.
Наконец, в пятой строке в ячейках I13 и J13 соответственно размещены ss reg — регрессионная сумма квадратов и ss resid — остаточная сумма квадратов.
На что следует в регрессионной статистике обратить особое внимание? Что для нас наиболее важно?
1. На сколько достоверно прогнозирует срок изготовления полученное уравнение функции y ? При высокой достоверности аппроксимации значение коэффициента детерминации r 2 близко к максимуму — к 1! Если r 2 <0,7…0,8, то различия между фактическими и расчетными значениями функции будут значительными, и применять полученную формулу для прогнозирования, скорее всего, нельзя.
В нашем примере r 2 =0,999388788. Это означает, что найденное уравнение функции y чрезвычайно точно определяет срок изготовления заказа по четырем входным данным. Вышесказанное подтверждается сравнительным анализом значений в ячейках F4…F16 и G4…G16 и указывает на существенную зависимость между сроком изготовления и данными о входящем в заказ металлопрокате.
2. Определим важность и полезность каждой из четырех переменных x 1 , x 2 , x 3 , x 4 в полученной формуле с помощью, так называемой, t -статистики.
2.1. Рассчитываем t 4 , t 3 , t 2 , t 1 , соответственно
в ячейке I16: t 4 = I9/I10 =26,44474886
в ячейке J16: t 3 = J9/J10 =-11,79198416
в ячейке K16: t 2 = K9/K10 =3,76748771
в ячейке L16: t 1 = L9/L10 =3,949105515
t i = m i / se i
2.2. Вычисляем двустороннее критическое значение t крит с уровнем достоверности α =0,05 (предполагается 5% ошибок) и количеством степеней свободы df =8
в ячейке M16: t крит =СТЬЮДРАСПОБР(0,05; J12) =2,306004133
Так как для всех t i справедливо неравенство | t i |> t крит , то это означает, что все выбранные переменные x i полезны при расчете сроков изготовления заказов – y .
Наиболее значимой переменной при прогнозировании в Excel сроков изготовления заказов y является x 4 , так как | t 4 |>| t 3 |>| t 1 |>| t 2 | .
3. Не является ли случайным полученное значение коэффициента детерминации r 2 ? Проверим это, используя F -статистику (распределение Фишера), которая характеризует «неслучайность» высокого значения коэффициента r 2 .
3.1. F -наблюдаемое значение считываем
в ячейке I12: 3270,188104
3.2. F -распределение имеет степени свободы v 1 и v 2 .
v 1 = k — df -1 =13-8-1=4
v 2 = df =8
Рассчитаем вероятность получения значения F -распределения большего, чем F -наблюдаемое
в ячейке I12: =FРАСП(I12;4;J12) =6,97468*10 -13
Так как вероятность получения большего значения F -распределения, чем наблюдаемое чрезвычайно мала, то из этого следует вывод — найденное уравнение функции y можно применять для прогнозирования сроков изготовления заказов. Полученное значение коэффициента детерминации r 2 не является случайным!
Заключение.
Применение функции MS Excel ЛГРФПРИБЛ почти не отличается от работы с функцией ЛИНЕЙН кроме вида уравнения искомой функции, которое принимает для рассмотренного примера следующий вид:
y =b *(m 1 x1 ) *(m 2 x2 )*(m 3 x3 )*(m 4 x4 )
Статистика множественной регрессии, которую рассчитывает функция ЛГРФПРИБЛ, базируется на линейной модели:
ln (y )=x 1 *ln (m 1 )+x 2 *ln (m 1 )...+x n *ln (m n )+ln (b )
Это означает, что значения, например, se i нужно сравнивать не с m i , а с ln (m i ) . (Подробнее об этом почитайте в справке MS Excel.)
Если в результате использования функции ЛГРФПРИБЛ коэффициент детерминации r 2 окажется ближе к 1, чем при использовании функции ЛИНЕЙН, то применение аппроксимирующей функции вида
y =b *(m 1 x 1 )*(m 2 x 2 )…*(m n x n ),
несомненно, является более целесообразным.
Если прогнозное значение функции y находится вне интервала фактических статистических значений y , то вероятность ошибки прогноза резко возрастает!
Для обеспечения высокой точности прогнозирования в Excel необходима точная и обширная статистическая база данных – информация об известных из практики результатах процессов. Но, даже имея в наличии такую базу, вы не будете застрахованы от ложных предположений и выводов. Процесс прогнозирования коварен и полон неожиданностей! Помните об этом всегда! Глубже вникайте в суть прогнозируемого процесса. Тщательней относитесь к выбору и назначению переменных. На полученные результаты всегда смотрите через «очки скептика». Такой подход поможет избежать серьезных ошибок в важных вопросах.
Для получения информации о выходе новых статей и для скачивания рабочих файлов программ прошу вас подписаться на анонсы в окне, расположенном в конце статьи или в окне вверху страницы.
Отзывы, вопросы и замечания, уважаемые читатели, пишите в комментариях внизу страницы.
ПРОШУ уважающих труд автора СКАЧАТЬ файл ПОСЛЕ ПОДПИСКИ на анонсы статей!
Отметим, что здесь рассматривалась сезонная компонента с длиной сезонности, равной 4 (4 квартала). Если исходные данные представлены помесячной динамикой (12 месяцев), то и сезонная компонента будет содержать 12 индексов сезонности вместо четырех. Процедура их вычисления при этом остается аналогичной.
Пример. Подбор наилучшей модели прогноза (модель Винтера)
Приведем пример выбора метода прогнозирования с использованием ранее рассмотренной информации на основе процедуры ППП Statgraphics «Forecasting– прогнозирование», как это указано на рис. 58.
Рис. 58. Выбор процедуры «прогнозирование» в ППП Statgraphics
Процедура «Forecasting» предусматривает возможность выбирать среди нескольких моделей прогноза (в том числе и модель Винтера) наилучшую модель, ориентируясь на ошибки прогноза.
Для того чтобы можно было использовать модель Винтера, необходимо в установках процедуры прогнозирования указать длину сезонности, а это автоматически включает процедуру учета сезонности при любой выбранной модели, что и отражено в отчете (рис. 59). Данная процедура позволяет выбирать одновременно 5 типов моделей, которые можно сравнивать по точности на основе ранее рассмотренных показателей точности прогноза.
В нашем случае наиболее точной оказалась модель (В) – линейный тренд (с учетом сезонной компоненты). Точность моделей можно сравнивать по различным показателям, например, по столбцу RMSE– стандартной ошибке прогноза (рис. 59).

Рис. 59. Отчет о выборе модели прогнозирования в ППП Statgraphicsс указанием длины сезонности
Перечислим модели, отраженные в отчете на рис. 59. В позиции (А) была назначена модель линейного экспоненциального сглаживания Холта. Как и отмечалось, для этой модели необходимы два параметра сглаживания: и. В позиции (В) была назначена модель линейного тренда. В позиции (С) – модель простого экспоненциального сглаживания. В позиции (D) – модель Брауна линейного экспоненциального сглаживания. В позиции (Е) – модель Винтера. Как видим, в последнем случае понадобилось три параметра сглаживания:,и.
Тот факт, что модель Винтера оказалась наименее точной, не означает, что она не пригодна для прогнозирования с учетом сезонной компоненты. Если убрать из установок процедуры прогнозирования указание на присутствие сезонности (не указывать длину сезонности), то среди всех выбранных модель Винтера будет наиболее точной, как это видно из отчета на рис. 60, в котором перечислен тот же набор моделей без указания на сезонность (модель Винтера здесь заменена квадратичной моделью Брауна).
Как видим, все приведенные модели имеют ошибку прогноза существенно бо льшую, чем модель Винтера на рис. 59.

Рис. 60. Отчет о выборе модели прогнозирования в ППП Statgraphicsс без указания длины сезонности
Отметим, что результаты прогнозирования по методу сезонной декомпозиции с линейным трендом, полученные ранее, оказались те же самые, что и при прогнозировании по линейному тренду на рис. 59 (сравните уравнение тренда на рис. 60 в позиции (В) и полученное в примере на основе табл. 3.1). Однако в последнем случае при проведении прогноза нет информации о составляющих элементов временного ряда (трендовой и сезонной), как это было получено ранее, но зато здесь прогноз может быть рассчитан в автоматическом режиме с указанием интервальных оценок.
Приведем прогноз по модели Винтера (рис. 61).

Рис. 61. Отчет о прогнозе по модели Винтера
На рис. 62 приведен график прогноза, иллюстрирующий результаты расчетов, приведенных на рис. 61.

Рис.62. График прогноза по модели Винтера
Пример. Моделирование сезонной компоненты на основе фиктивных переменных
Как отмечалось выше (п. 2.3.4), сезонную компоненту можно моделировать и на основе фиктивных переменных. Выберем в качестве примера аддитивную модель сезонной декомпозиции и проиллюстрируем ее сходство с моделью с фиктивными переменными.
Пусть имеются данные о продажах продукции фирмы (см. информацию в столбце Dataна рис. 63). Анализ горизонтального графика ряда (рис. 64) показал наличие тренда с сезонной компонентой. Применим метод сезонной декомпозиции (аддитивную модель), результаты которого показаны на рис. 63.

Рис. 63. Отчет о расчетах по методу сезонной декомпозиции по аддитивной модели

Рис. 64. Горизонтальный график ряда
Ниже приведены результаты усреднения сезонно-случайной компоненты в виде показателей, указывающих, на сколько усл. ден. единиц продажи выше или ниже средних по тренду.

Далее приведен график этих показателей (рис. 66). Слово «индекс» взят в кавычки потому, что здесь этот показатель выражен в абсолютных единицах изучаемого процесса (усл. ден. ед.), а не в долях или процентах, как это обычно присуще индексам в статистике.

Рис. 66. График «индекса» сезонности
По приведенным расчетным показателям заключаем, что продажи в первом квартале в среднем на 67,3 усл. ден. ед. меньше, чем по тренду, а в остальных кварталах – выше на соответствующую величину.
Приведенный ниже (рис. 67) график данных, исправленных на сезонность показывает наличие тренда, который можно принять за линейный. Рассчитаем по этим данным линейный тренд.

Рис. 67. График данных, исправленных на сезонность
Результаты расчета линейного тренда приведены ниже (рис. 68).

Рис. 68. Уравнение линейного тренда (R 2 = 87,5%,d= 1,82)
Итак, уравнение тренда имеет вид
 = 223.16 + 4.85t.
= 223.16 + 4.85t.
Проведем теперь моделирование сезонной компоненты с помощью фиктивных переменных. Как уже отмечалось, число таких переменных должно быть на единицу меньше, чем число уровней моделируемого явления. Т. к. у нас квартальные данные, то таких переменных будет три: х 1 , х 2 и х 3 . Каждая из них равна единице для соответствующего квартала и равна нулю – для остальных, как это отражено на рис. 69.

Рис. 69. Исходные данные для модели с фиктивными переменными
Результаты множественной регрессии с фиктивными переменными приведены на рис. 70.

Рис. 70. Отчет о множественной регрессии при моделировании сезонной компоненты с помощью фиктивных переменных
Итак, уравнение регрессии имеет вид (с округлением)
 = 240.9 + 4,94t– 82,71x 1 – 5,27x 2 + 14,04x 3 .
= 240.9 + 4,94t– 82,71x 1 – 5,27x 2 + 14,04x 3 .
Таким образом, по сравнению с четвертым кварталом продажи в первом квартале ниже на 82,7 1 ед., во втором – ниже на 5,27 ед., а в третьем – выше на 14,04 ед. Средний постоянный уровень продаж равен 240.9 ед., а среднее ежеквартальное увеличение продаж равно 4,94 ед. (коэффициент при t).
Аналогичные результаты можно получить, сравнивая сезонные «индексы» для аддитивной модели. Так, разница между такими индексами для соответствующих кварталов следующая: S 4 –S 1 = 20,26 – (–67,32) = 87,58;S 4 –S 2 = 20,26 – 13,56 = 6,7;
S 4 –S 3 = 20,26 – 33,49 = –13,23.
Задания для самостоятельной работы
Задание 1
К следующим временным рядам подобрать лучшую линию тренда в виде аналитической кривой:
а) 21,6 22,9 25,5 21,9 23,9 27,5 31,5 29,7 28,6 31,4 32,1 31,2;
б) 146 106 123 89 97 74 80 53 56 35.
Изобразить в системе координат исходные данные и выбранную линию тренда.
Ниже (рис. 71 и рис. 72) приведены отчеты о решении задач с помощью статистического ППП. Вам необходимо его проанализировать и сделать соответствующие выводы по аналогии с тренировочным примером.

Рис. 71. Информация для решения задачи а)

Рис. 72. Информация для решения задачи б)
Прогноз сделать по линейному и квадратичному тренду.
Задание 2
Имеется следующая информация о потреблении электроэнергии жителями города за 4 года по кварталам (рис.73 в столбце Data ).
Используя результаты расчетов (рис. 73), построить график исходных данных и линию тренда по центрированным скользящим средним (столбец Trend - Cycle рис.73). Вычислить индексы сезонности, усреднив показатели сезонности (столбецSeasonality ) по соответствующим кварталам (например, для 3-го квартала необходимо сосчитать среднюю арифметическую из чисел с номерами 3, 7, и 11 в столбцеSeasonality и т. д.).

Рис. 73. Информация для анализа задачи из задания 2
Построить график индексов сезонности.
Спрогнозировать потребление электроэнергии по линии тренда (выбрать лучшую линию тренда по данным на рис. 58)

Рис. 74. Окно отчета о подборе линии тренда
Скорректировать прогноз по тренду с помощью индексов сезонности.
Задание 3
Для следующего ряда данных об объемах продаж некоторой фирмы по кварталам спрогнозировать объемы продаж на очередной 6-й год, выбрав наилучший тип модели:
350, 200, 150, 400, 550, 350, 250, 550, 550, 400, 350, 600, 750, 500, 400, 650, 850, 600, 450, 700.
Задание 4
Спрогнозировать на очередные 5 периодов процесс, характеризующийся следующими данными за 40 прошедших периодов, подобрав наилучший вид модели:
10,4 10,34 10,55 10,46 10,82 10,91 10,87 10,67 11,11 10,00 11,20 11,27 11,44 11,52 12,10 11,83 12,62 12,41 12,43 12,73 13,01 12,74 12,73 12,76 12,92 12,64 12,79 13,06 12,69 13,01 12,90 13,12 12,47 12,94 13,1 12,91 13,39 13,13 13,34 13,14.

