Теги: Двоичное дерево поиска. БДП. Итреативные алгоритмы работы с двоичным деревом поиска.
Двоичное дерево поиска. Итеративная реализация.
Д воичные деревья – это структуры данных, состоящие из узлов, которые хранят значение, а также ссылку на свою левую и правую ветвь. Каждая ветвь, в свою очередь, является деревом. Узел, который находится в самой вершине дерева принято называть корнем (root), узлы, находящиеся в самом низу дерева и не имеющие потомков называют листьями (leaves). Ветви узла называют потомками (descendants). По отношению к своим потомкам узел является родителем (parent) или предком (ancestor). Также, развивая аналогию, имеются сестринские узлы (siblings – родные братья или сёстры) – узлы с общим родителем. Аналогично, у узла могут быть дяди (uncle nodes) и дедушки и бабушки (grandparent nodes). Такие названия помогают понимать различные алгоритмы.
Двоичное дерево. На этом рисунке узел 10 корень, 7 и 12 его наследники. 6, 9, 11, 14 - листья. 7 и 12, также как и 6 и 9 являются сестринскими узлами, 10 - это дедушка узла 6, а 12 - дядя узла 6 и узла 9
Двоичные деревья одна из самых простых структур (по сравнению, например, с другими деревьями). Они обычно реализуют самый базовый и самый естественный способ классификации элементов – делят их по определённому признаку, размещая одну группу в левом поддереве, а другую группу в правом. В поддеревьях рекурсивно поддерживается такой же порядок, за счёт чего узлы дерева упорядочиваются.
Такое размещение – слева меньше, справа больше – не обязательно, можно располагать элементы, которые меньше, справа. Отношение БОЛЬШЕ и МЕНЬШЕ – это не обязательно естественная сортировка по величине, это некоторая бинарная операция, которая позволяет разбить элементы на две группы.
Для реализации бинарного дерева поиска будем использовать структуру Node, которая содержит значение, ссылку на правое и левое поддерево, а также ссылку на родителя. Ссылка на родительский узел, в принципе, не является обязательной, однако сильно упрощает и ускоряет все алгоритмы. Далее, ради тренировки, мы ещё рассмотрим реализацию без ссылки на родителя.
ЗАМЕЧАНИЕ: мы рассматриваем случай, когда в дереве все значения разные и не равны NULL. Деревья с повторяющимися узлами рассмотрим позднее.
Обычно в качестве типа данных мы используем void* и далее передаём функции сравнения через указатели. В этот раз будем использовать пользовательский тип и макросы.
Typedef int T; #define CMP_EQ(a, b) ((a) == (b)) #define CMP_LT(a, b) ((a) < (b)) #define CMP_GT(a, b) ((a) > (b)) typedef struct Node { T data; struct Node *left; struct Node *right; struct Node *parent; } Node;
Сначала, как обычно, напишем функцию, которая создаёт новый узел. Она принимает в качестве аргументов значение и указатель на своего родителя. Корневой элемент не имеет родителя, значение указателя parent равно NULL.
Node* getFreeNode(T value, Node *parent) { Node* tmp = (Node*) malloc(sizeof(Node)); tmp->left = tmp->right = NULL; tmp->data = value; tmp->parent = parent; return tmp; }
Разберёмся со вставкой. Возможны следующие ситуации
- 1) Дерево пустое. В этом случае новый узел становится корнем ДДП.
- 2) Новое значение меньше корневого. В этом случае значение должно быть вставлено слева. Если слева уже стоит элемент, то повторяем эту же операцию, только в качестве корневого узла рассматриваем левый узел. Если слева нет элемента, то добавляем новый узел.
- 3) Новое значение больше корневого. В этом случае новое значение должно быть вставлено справа. Если справа уже стоит элемент, то повторяем операцию, только в качестве корневого рассматриваем правый узел. Если справа узла нет, то вставляем новый узел.
Пусть нам необходимо поместить в ДДП следующие значения
10 7 9 12 6 14 11 3 4
Первое значение становится корнем.
Дерево с одним узлом. Равных NULL потомков не рисуем
Второе значение меньше десяти, так что оно помещается слева.
Если значение меньше, то помещаем его слева
Число 9 меньше 10, так что узел должен располагаться слева, но слева уже стоит значение. 9 больше 7, так что новый узел становится правым потомком семи.
Двоичное дерево поиска после добавления узлов 10, 7, 9
Число 12 помещается справа от 10.
6 меньше 10 и меньше 7...
Добавляем оставшиеся узлы 14, 3, 4, 11
Функция, добавляющая узел в дерево
Два узла. Первый – вспомогательная переменная, чтобы уменьшить писанину, второй – тот узел, который будем вставлять.
Node *tmp = NULL; Node *ins = NULL;
Проверяем, если дерево пустое, то вставляем корень
If (*head == NULL) { *head = getFreeNode(value, NULL); return; }
Проходим по дереву и ищем место для вставки
Tmp = *head;
Пока не дошли до пустого узла
While (tmp) {
Если значение больше, чем значение текущего узла
If (CMP_GT(value, tmp->data)) {
Если при этом правый узел не пустой, то за корень теперь считаем правую ветвь и начинаем цикл сначала
If (tmp->right) { tmp = tmp->right; continue;
Если правой ветви нет, то вставляем узел справа
} else { tmp->right = getFreeNode(value, tmp); return; }
Также обрабатываем левую ветвь
} else if (CMP_LT(value, tmp->data)) { if (tmp->left) { tmp = tmp->left; continue; } else { tmp->left = getFreeNode(value, tmp); return; } } else { exit(2); } }
Void insert(Node **head, int value) { Node *tmp = NULL; Node *ins = NULL; if (*head == NULL) { *head = getFreeNode(value, NULL); return; } tmp = *head; while (tmp) { if (CMP_GT(value, tmp->data)) { if (tmp->right) { tmp = tmp->right; continue; } else { tmp->right = getFreeNode(value, tmp); return; } } else if (CMP_LT(value, tmp->data)) { if (tmp->left) { tmp = tmp->left; continue; } else { tmp->left = getFreeNode(value, tmp); return; } } else { exit(2); } } }
Рассмотрим результат вставки узлов в дерево. Очевидно, что структура дерева будет зависеть от порядка вставки элементов. Иными словами, форма дерева зависит от порядка вставки элементов.
Если элементы не упорядочены и их значения распределены равномерно, то дерево будет достаточно сбалансированным, то есть путь от вершины до всех листьев будет одинаковый. В таком случае максимальное время доступа до листа равно log(n), где n – это число узлов, то есть равно высоте дерева.
Но это только в самом благоприятном случае. Если же элементы упорядочены, то дерево не будет сбалансировано и растянется в одну сторону, как список; тогда время доступа до последнего узла будет порядка n. Это слабая сторона ДДП, из-за чего применение этой структуры ограничено.
Дерево, которое получили вставкой чередующихся возрастающей и убывающей последовательностей (слева) и полученное при вставке упорядоченной последовательности (справа)
Для решения этой проблемы можно производить балансировку дерева, или использовать структуры, которые автоматически проводят самобалансировку во время вставки и удаления.
Поиск в дереве
И звестно, что слева от узла располагается элемент, который меньше чем текущий узел. Из чего следует, что если у узла нет левого наследника, то он является минимумом в дереве. Таким образом, можно найти минимальный элемент дерева
Node* getMinNode(Node *root) { while (root->left) { root = root->left; } return root; }
Аналогично, можно найти максимальный элемент
Node* getMaxNode(Node *root) { while (root->right) { root = root->right; } return root; }
Опять же, если дерево хорошо сбалансировано, то поиск минимума и максимума будет иметь сложность порядка log(n), а в случае плохой балансировки стремится к n.
Поиск нужного узла по значению похож на алгоритм бинарного поиска в отсортированном массиве. Если значения больше узла, то продолжаем поиск в правом поддереве, если меньше, то продолжаем в левом. Если узлов уже нет, то элемент не содержится в дереве.
Node *getNodeByValue(Node *root, T value) { while (root) { if (CMP_GT(root->data, value)) { root = root->left; continue; } else if (CMP_LT(root->data, value)) { root = root->right; continue; } else { return root; } } return NULL; }
Удаление узла
С уществует три возможных ситуации.
- 1) У узла нет наследников (удаляем лист). Тогда он просто удаляется, а его родитель обнуляет указатель на него.
Удаляем лист
Просто исключаем его из дерева
- 2) У узла один наследник. В этом случае узел подменяется своим наследником.
- 3) У узла оба наследника. В этом случае узел не удаляем, а заменяем его значение на максимум левого поддерева. После этого удаляем максимум левого поддерева. (Напомню, что мы условились, что слева элементы меньше корневого).
У узла 7 два наследника. Находим максимум его левого поддерева (это 6)
Узел не удаляем, а копируем на его место значение максимума левого поддерева и удаляем этот узел
У узла 6 один наследник
Копируем на его место единственного наследника
Максимум левого поддерева имеет не более одного наследника, так что он удаляется просто. Известно, что все значения слева от корня меньше корня. Соответственно, максимум левого поддерева будет, с одной стороны, больше всех элементов левого поддерева, с другой стороны меньше всех значений правого поддерева.
Наша функция будет принимать в качестве аргумента узел, который необходимо удалить.
If (target->left && target->right) { //Оба наследника есть } else if (target->left) { //Есть только левый наследник } else if (target->right) { //Есть только правый наследник } else { //Нет наследников } free(target);
Если нет наследников, то нужно узнать, каким поддеревом относительно родителя является узел
If (target == target->parent->left) { target->parent->left = NULL; } else { target->parent->right = NULL; }
Если есть только правый или только левый наследник, подменяем наследником удаляемый узел. Перед этим нужно узнать, правым или левым наследником является удаляемый узел.
If (target == target->parent->left) { target->parent->left = target->left; } else { target->parent->right = target->left; }
If (target == target->parent->right) { target->parent->right = target->right; } else { target->parent->left = target->right; }
Если оба наследника, то сначала находим максимум левого поддерева
Node *localMax = findMaxNode(target->left);
Затем подменяем значение удаляемого узла на него
Target->data = localMax->data;
После чего удаляем этот узел
RemoveNodeByPtr(localMax);
return;
Здесь мы использовали рекурсию, хотя я обещал этого не делать. Вызов будет всего один, так как известно, что максимум не содержит обоих наследников и является правым наследником
своего родителя. Если хотите заменить вызов функции, то придётся скопировать оставшийся код.
Void removeNodeByPtr(Node *target) { if (target->left && target->right) { Node *localMax = findMaxNode(target->left); target->data = localMax->data; removeNodeByPtr(localMax); return; } else if (target->left) { if (target == target->parent->left) { target->parent->left = target->left; } else { target->parent->right = target->left; } } else if (target->right) { if (target == target->parent->right) { target->parent->right = target->right; } else { target->parent->left = target->right; } } else { if (target == target->parent->left) { target->parent->left = NULL; } else { target->parent->right = NULL; } } free(target); }
Упростим работу и сделаем обёртку вокруг функции, чтобы она удаляла узел по значению
Void deleteValue(Node *root, T value) { Node *target = getNodeByValue(root, value); removeNodeByPtr(target); }
Для проверки можно ввести функцию печати дерева. Так как мы ещё не научились обходить деревья, вывод осавляет желать лучшего.
Void printTree(Node *root, const char *dir, int level) { if (root) { printf("lvl %d %s = %d\n", level, dir, root->data); printTree(root->left, "left", level+1); printTree(root->right, "right", level+1); } }
Проверка
Void main() { Node *root = NULL; insert(&root, 10); insert(&root, 12); insert(&root, 8); insert(&root, 9); insert(&root, 7); insert(&root, 3); insert(&root, 4); printTree(root, "root", 0); printf("max = %d\n", findMaxNode(root)->data); printf("min = %d\n", findMinNode(root)->data); deleteValue(root, 4); printf("parent of 7 is %d\n", getNodeByValue(root, 7)->parent->data); printTree(root, "root", 0); deleteValue(root, 8); printTree(root, "root", 0); printf("------------------\n"); deleteValue(root, 10); printTree(root, "root", 0); getch(); }
Абстрактное бинарное дерево
Лекция Деревья
Деревья (trees) используются для представления отношения. Все деревья являются иерархическими по своей сути. Интуитивное значение этого термина состоит в том, что между узлами дерева существует отношение "родительский-дочерний". Если ребро соединяет узел n и узел т, причем узел п находится выше узла т, то узел n считается родителем (parent) узла т, а узел т - его дочерним узлом (child) . В дереве, изображенном на рис. 10.1, узлы В и С являются дочерними по отношению к узлу А. Дочерние узлы, имеющие одного и того же родителя, - например, узлы В и С - называются братьями (siblings) . Каждый узел дерева имеет по крайней мере одного родителя, причем в дереве существует только один узел, не имеющий предков. Такой узел называется корнем дерева (root) . На рис. 10.1 корнем является узел А. Узел, у которого нет дочерних узлов, называется листом дерева (leaf). Листьями дерева, изображенного на рис. 10.1, являются узлы С, D, Е и F.
Рис. 10.1. Дерево общего в
Отношения между родительским и дочерним узлом с абстрактной точки зрения является отношением между предком (ancestor) и потомком (descendant). На рис. 10.1 узел А является предком узла Д следовательно, узел D является потомком узла А. Не все узлы могут быть связаны отношениями "предок-потомок": узлы В и С, например, не связаны родственными отношениями. Однако корень любого дерева является предком каждого его узла. Поддеревом (subtree) называется любой узел дерева со всеми его потомками. Поддеревом узла п является поддерево, корнем которого является узел n. Например, на рис. 10.2 показано поддерево дерева, изображенного на рис. 10.1. Корнем этого поддерева является узел В, а само поддерево является поддеревом узла А.
С формальной точки зрения, дерево общего вида (general tree) T представляет собой множество, состоящее из одного или нескольких узлов, принадлежащих непересекающимся подмножествам, указанным ниже.
Отдельный узел r, корень.
Множество поддеревьев корня r.
Бинарное дерево (binary tree) - это множество узлов Т, таких что
Множество Т пусто, или
Множество Т распадается на три непересекающихся подмножества:
Отдельный корень r, корень;
Два возможно пустых поддерева бинарного дерева, которые называются левым и правым поддеревьями (leaf and right subtrees) корня r, соответственно.

В качестве иллюстрации использования бинарных деревьев для представления данных в иерархическом виде рассмотрим рис. 10.4. На этом рисунке бинарные деревья представляют алгебраические выражения, содержащие бинарные операторы +, -, * и /. Для представления выражения а-b оператор помещается в корневой узел, а операнды а и b- в его левый и правый дочерние узлы, соответственно (рис. 10.4). На рис. 10.4, б представлено выражение a-b/с, где поддерево представляет подвыражение b/с. Аналогичная ситуация показана на рис. 10.4, в, где изображено выражение (а-b)*с. В узлах этих деревьев хранятся операнды выражений, а в остальных узлах - операторы. Скобки в этих деревьях не представлены. Бинарное дерево создает иерархию операций, т.е. дерево однозначно определяет порядок вычисления выражения.
 |
Рис. 10.4. Бинарные деревья, представляющие алгебраические выражения
Бинарное дерево поиска - это бинарное дерево, некоторым образом упорядоченное в соответствии со значениями, содержащимися в его узлах. Каждый узел п бинарного дерева поиска обладает следующими тремя свойствами:
Значение узла п больше всех значений, содержащихся в левом поддереве TL.
Значение узла п меньше всех значений, содержащихся в правом поддереве ТR.
Деревья TL и ТR являются деревьями бинарного поиска.
На рис. 10.5 показан пример бинарного дерева поиска. Как следует из его названия, это дерево обеспечивает возможности поиска конкретного элемента. Позднее мы рассмотрим эту структуру данных более подробно.
 |
Высота деревьев. Деревья могут иметь разную форму. Например, хотя деревья, изображенные на рис. 10.6, состоят из одинаковых узлов, они имеют совершенно разную структуру. Каждое из этих деревьев содержит семь узлов, но некоторые деревья "выше" других. Высота (height) дерева - это количество узлов, расположенных на самом длинном пути от корня к листу. Например, высота деревьев, показанных на рис. 10.6, равна 3, 5 и 7, соответственно. Интуитивное представление о высоте деревьев может привести к заключению, что их высота равна 2, 4 и 6, соответственно. Действительно, многие авторы используют именно интуитивное определение высоты дерева (подсчитывая количество ребер на самом длинном пути от корня до дерева. - Прим. ред.). Однако принятое нами определение позволяет более четко формулировать многие алгоритмы и свойства деревьев.
 |
Полное, совершенное и сбалансированное дерево. В полном бинарном дереве(full binary tree), имеющем высоту h, все узлы, расположенные на уровнях, меньших уровня h, имеют по два дочерних узла. На рис. 10.7 представлено полное бинарное дерево, имеющее высоту, равную 3. Каждый узел полного бинарного дерева имеет левое и правое поддерево, имеющие одинаковую высоту . Среди всех бинарных деревьев, высота которых равна h, полное бинарное дерево имеет максимально возможное количество листьев, и все они расположены на уровне h. Проще говоря, в полном бинарном дереве нет пропущенных узлов.

Доказывая свойства полных бинарных деревьев, подсчитывая количество их узлов, удобно пользоваться рекурсивным определением.
Если дерево Т пусто, то оно является полным бинарным деревом, имеющим
высоту, равную 0.
Если дерево T не пусто, и его высота равна h > 0, то дерево T является полным бинарным деревом, если поддеревья его корня являются полными бинарными деревьями, имеющими высоту h-1.
Это определение хорошо отражает рекурсивную природу бинарного дерева.
Совершенное бинарное дерево (complete binary tree), имеющее высоту h, - это бинарное дерево, которое является полным вплоть до уровня h-1, а уровень h заполнен слева направо так, как показано на рис. 10.8.

Рис. 10.8. Совершенное бинарное дерево
Очевидно, что полное бинарное дерево является совершенным.
Бинарное дерево называется сбалансированным по высоте (height balanced), или просто сбалансированным (balanced), если высота правого поддерева любого его узла отличается от высоты левого поддерева не больше, чем на 1. Бинарные деревья, изображенные на рис. 10.8 и 10.6, а, являются сбалансированными, а деревья, представленные на рис. 10.6, б и 10.6, в - нет. Совершенное бинарное дерево является сбалансированным. Итак, повторим кратко введенные понятия.
Абстрактное бинарное дерево
B бинарном дереве существует несколько способов обхода. Стандартными являются три порядка обхода дерева: прямой, симметричный и обратный. Все они описываются в следующем разделе. Над абстрактным бинарным деревом выполняются следующие операции.
Двоичное дерево – вид связного ациклического (не имеющего циклов) графа, характерный тем, что у каждого из его узлов имеется не более двух потомков (связанных узлов, находящихся иерархически ниже).
Определения следующего абзаца не относятся непосредственно к двоичным деревьям, а скорее к вообще, поэтому тем, у кого не возникает проблем с понятиями можно перейти к следующему абзацу.
В двоичном дереве есть только один узел, у которого нет предка, он называется корнем . Конечные узлы – листья . Если у корня отсутствует предок, то у листьев – потомки. Все вершины помимо корня и листьев называются узлами ветвления . Длина пути от корня до узла определяет уровень этого самого узла. Уровень корня дерева всегда равен нулю, а уровень всех его потомков определяется удаленностью от него. Например, узлы F и L (рис. ниже) расположены на первом уровне, а U и B – на третьем.
Связный граф является деревом тогда и только тогда, когда P - A =1 , где P – количество вершин в графе, а A – количество ребер, поскольку в любом дереве с n вершинами, должно быть n -1 ребро. Это справедливо и для бинарного дерева, так как оно входит в класс деревьев. А увидеть отличительные признаки бинарного дерева , можно просто зная его определение. Достаточно взглянуть на рисунок 1, чтобы понять является ли изображенный на нем граф бинарным деревом.
Во-первых, он связный и не имеет ни одного цикла (следовательно, имеем дело с деревом), во-вторых из каждого узла исходит не больше двух ребер (если бы граф был неориентированным, то допускалось три исходящих ребра), что указывает на главный признак двоичного дерева. Но существует и немного другой способ проверить является ли дерево бинарным. Составим список, в левом столбце которого будут содержаться номера уровней, а в правом – число вершин, лежащих на каждом из них:
Обозначим уровень символом k
, а количество вершин n
, тогда для бинарного дерева будет справедливо равенство n
≤
2
k
, т. е. количество вершин на k
-ом уровне не может иметь значение большее, чем степень двойки этого уровня. Для доказательства этого достаточно построить полное дерево, все уровни которого содержат максимально возможное для двоичного дерева количество вершин: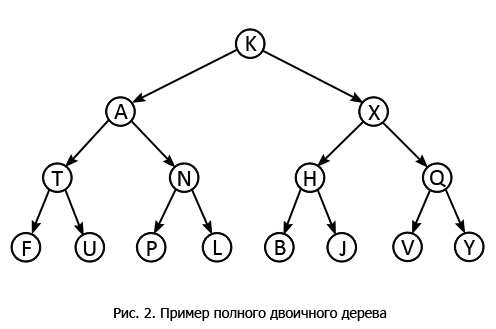
Продолжая построение, будем получать на каждом новом уровне число вершин равное k -ой степени двойки, а их общее количество вычисляется по формуле:Для рисунка 2 формула раскрывается так: 2 0 +2 1 +2 2 +2 3 =15.
Операция, при которой вершины дерева поочередно просматриваются и каждая только один раз, называется обходом дерева . Выделяют четыре основных метода обхода:
- обход в ширину;
- прямой обход;
- обратный обход;
- симметричный обход;
Обход в ширину – это поуровневая обработка узлов слева на право. Работа метода заключается в просмотре всех вершин, начиная с некоторой вершины на n-ом уровне.
Возьмем нулевой уровень за начальный (рис. 2), и, начиная с вершины K , будем методом обхода в ширину поочередно двигаться вниз, просматривая вершины в следующем порядке: K A X T N H Q F U P L B J V Y.
Обход в прямом порядке вначале предполагает обработку узлов предков, а потом их потомков, то есть сначала посещается вершина дерева, далее левое и правое поддеревья, именно в описанном порядке. Для нашего дерева последовательность прямого обхода такая: K A T F U N P L X H B J Q V Y.
Обход в обратном порядке противоположен прямому обходу. Первыми осматриваются потомки, а уже затем предки, иначе говоря, первоначально обращение идет к элементам нижних уровней левого поддерева, потом то же самое с элементами правого, и в конце осматривается корень. Обратный обход дерева с рисунка 2: F U T P L N A B J H V Y Q X K.
Обход в симметричном порядке заключается в посещении левого узла, перехода в корень и оттуда в правый узел. Все для того же дерева узлы будут осмотрены в следующем порядке: F T U A P N L K B H J X V Q Y.
На практике используются не просто бинарные деревья, а их частные случаи, например, такие как двоичное дерево поиска, АВЛ-дерево, двоичная куча и другие.
Древовидной структурой данных называется конечное множество элементов-узлов, между которыми существуют отношения – связь исходного и порожденного.
Если использовать рекурсивное определение, предложенное Н. Виртом, то древовидная структура данных с базовым типом t – это либо пустая структура, либо узел типа t, с которым связано конечное множество древовидных структур с базовым типом t, называемых поддеревьями.
Если узел у находится непосредственно под узлом х, то узел у называется непосредственным потомком узла х, а х – непосредственным предком узла у, т. е., если узел х находится на i-ом уровне, то соответственно узел у находится на (i + 1) – ом уровне.
Максимальный уровень узла дерева называется высотой или глубиной дерева. Предка не имеет только один узел дерева – его корень.
Узлы дерева, у которых не имеется потомков, называются терминальными узлами (или листами дерева). Все остальные узлы называются внутренними узлами. Количество непосредственных потомков узла определяет степень этого узла, а максимально возможная степень узла в данном дереве определяет степень дерева.
Предков и потомков нельзя поменять местами, т. е. связь исходного и порожденного действует только в одном направлении.
Если пройти от корня дерева к некоторому конкретному узлу, то количество ветвей дерева, которое при этом будет пройдено, называется длиной пути для этого узла. Если все ветви (узлы) у дерева упорядочены, то дерево называется упорядоченным.
Частным случаем древовидных структур являются бинарные деревья. Это деревья, в которых каждый потомок имеет не более двух потомков, называемых левым и правым поддеревьями. Таким образом, бинарное дерево – это древовидная структура, степень которой равна двум.
Упорядоченность бинарного дерева определяется по следующему правилу: каждому узлу соответствует свое ключевое поле, и для каждого узла значение ключа больше всех ключей в его левом поддереве и меньше всех ключей в его правом поддереве.
Дерево, степень которого больше двух, называется сильноветвящимся.
2. Операции над деревьями
I. Построение дереваПриведем алгоритм построения упорядоченного дерева.
1. Если дерево пусто, то данные переносятся в корень дерева. Если же дерево не пусто, то осуществляется спуск по одной из его ветвей таким образом, чтобы упорядоченность дерева не нарушалась. В результате новый узел становится очередным листом дерева.
2. Чтобы добавить узел в уже существующее дерево, можно воспользоваться вышеприведенным алгоритмом.
3. При удалении узла из дерева следует быть внимательным. Если удаляемый узел является листом, или же имеет только одного потомка, то операция проста. Если же удаляемый узел имеет двух потомков, то необходимо будет найти узел среди его потомков, который можно будет поставить на его место. Это нужно в силу требования упорядоченности дерева.
Можно поступить таким образом: поменять удаляемый узел местами с узлом, имеющем самое большое значение ключа в левом поддереве, или с узлом, имеющем самое малое значение ключа в правом поддереве, а затем удалить искомый узел как лист.
II. Поиск узла с заданным значением ключевого поляПри осуществлении этой операции необходимо совершить обход дерева. Необходимо учитывать различные формы записи дерева: префиксную, инфиксную и постфиксную.
Возникает вопрос: каким образом представить узлы дерева, чтобы было наиболее удобно работать с ними? Можно представлять дерево с помощью массива, где каждый узел описывается величиной комбинированного типа, у которой информационное поле символьного типа и два поля ссылочного типа. Но это не совсем удобно, так как деревья имеют большое количество узлов, заранее не определенное. Поэтому лучше всего при описании дерева использовать динамические переменные. Тогда каждый узел представляется величиной одного типа, которая содержит описание заданного количества информационных полей, а количество соответствующих полей должно быть равно степени дерева. Логично отсутствие потомков определять ссьшкой nil. Тогда на языке Pascal описание бинарного дерева может выглядеть следующим образом:
TYPE TreeLink = ^Tree;
Inf: <тип данных>;
Left, Right: TreeLink;
3. Примеры реализации операций
1. Построить дерево из n узлов минимальной высоты, или идеально сбалансированное дерево (количество узлов левого и правого поддеревьев такого дерева должны отличаться не более чем на единицу).
Рекурсивный алгоритм построения:
1) первый узел берется в качестве корня дерева.
2) тем же способом строится левое поддерево из nl узлов.
3) тем же способом строится правое поддерево из nr узлов;
nr = n – nl – 1. В качестве информационного поля будем брать номера узлов, вводимые с клавиатуры. Рекурсивная функция, реализующая данное построение, будет выглядеть следующим образом:
Function Tree(n: Byte) : TreeLink;
Var t: TreeLink; nl,nr,x: Byte;
If n = 0 then Tree:= nil
nr = n – nl – 1;
writeln("Введите номер вершины ");
t^.left:= Tree(nl);
t^.right:= Tree(nr);
2. В бинарном упорядоченном дереве найти узел с заданным значением ключевого поля. Если такого элемента в дереве нет, то добавить его в дерево.
Procedure Search(x: Byte; var t: TreeLink);
Else if x < t^.inf then
Search(x, t^.left)
Else if x > t^.inf then
Search(x, t^.right)
{обработка найденного элемента}
3. Написать процедуры обхода дерева в прямом, симметричном и обратном порядке соответственно.
3.1. Procedure Preorder(t: TreeLink);
If t <> nil then
Writeln(t^.inf);
Preorder(t^.left);
Preorder(t^.right);
3.2. Procedure Inorder(t: TreeLink);
If t <> nil then
Inorder(t^.left);
Writeln(t^.inf);
Inorder(t^.right);
3.3. Procedure Postorder(t: TreeLink);
If t <> nil then
Postorder(t^.left);
Postorder(t^.right);
Writeln(t^.inf);
4. В бинарном упорядоченном дереве удалить узел с заданным значением ключевого поля.
Опишем рекурсивную процедуру, которая будет учитывать наличие требуемого элемента в дереве и количество потомков этого узла. Если удаляемый узел имеет двух потомков, то он будет заменен самым большим значением ключа в его левом поддереве, и только после этого он будет окончательно удален.
Procedure Delete1(x: Byte; var t: TreeLink);
Var p: TreeLink;
Procedure Delete2(var q: TreeLink);
If q^.right <> nil then Delete2(q^.right)
p^.inf:= q^.inf;
Writeln("искомого элемента нет")
Else if x < t^.inf then
Delete1(x, t^.left)
Else if x > t^.inf then
Delete1(x, t^.right)
If p^.left = nil then
If p^.right = nil then

